The reading is complex primarily because of all the theoretical explanations of terms and comparisons to a universal understanding of information/data, etc… For someone who has ventured into computer science and held an interest in data information and how computers function/perform, specific definitions for things like environmental information were not very direct. A good portion of the reading itself felt like I was reading through some philosophical readings about the existence of things and how one knows something exists and does not exist…
Certain aspects of the reading, however, were helpful. The breakdown of terms such as primary data, secondary data, metadata, operational data, & derivative data was done relatively concisely with good examples. The different charts throughout the reading helped visualize some of the explanations about data and information which in return allowed me to understand how one begins from “wild data”/ dedomena and arrives at processed data/information.
The overall understanding that I arrived at, is that information results from the combination of multiple or a single piece of data. There are multiple ways that data can be analyzed/interpreted and that depends on the state in which and where it was found.
For our typical use, we convert the data into “processed data/information” through a series of true/false tests, which is something a digital computer can do via a binary system.
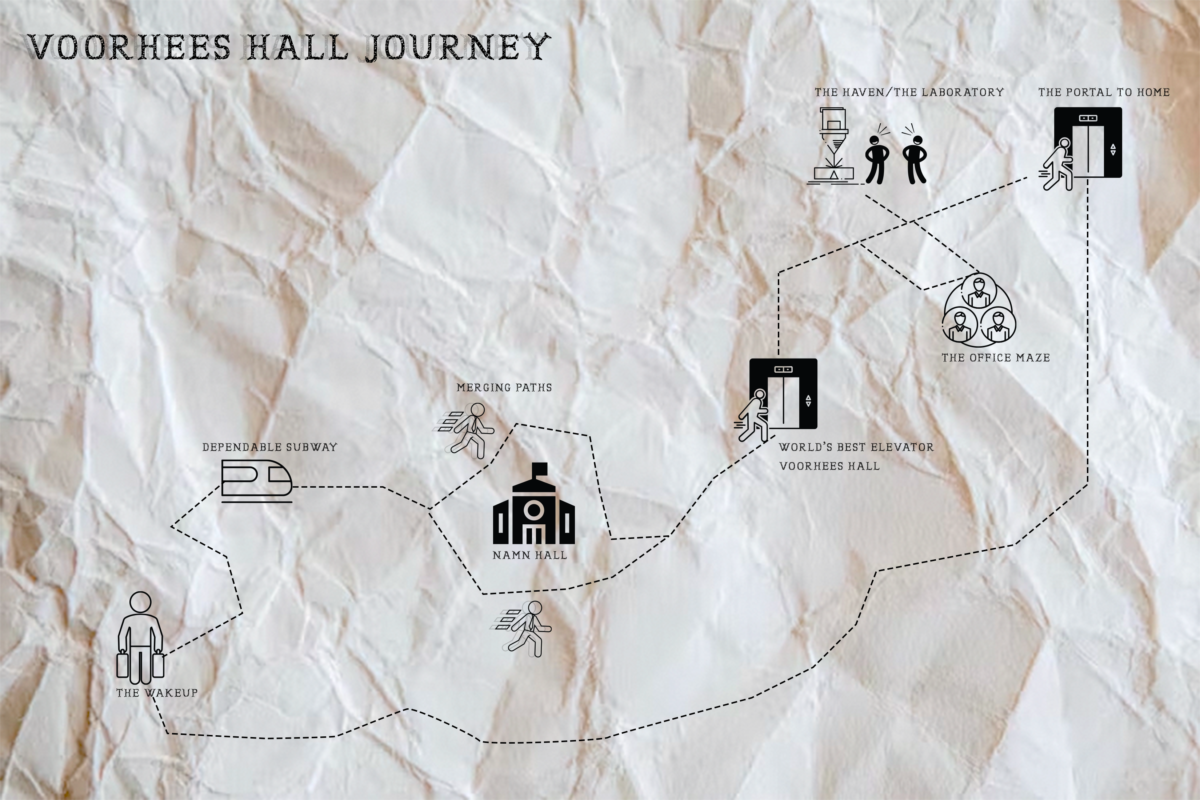
Mapping Exercise


Leave a Reply