As a college student, you probably can’t imagine a time when there was no internet. Now, it’s probably an essential part of your studies. With the widespread use of the internet, they’re a lot of tools at students’ disposal for research and editing when it’s time to write an essay or research paper. It is a headache and time consuming effort when students need to find a lot of sources for their research. During the process of doing research papers, there is a great deal of information to sift through, such as scholarly sources, internet sources, news sources and primary sources. No student has time to go through all these sources, that does not help with the exact information they are looking for. As is the case, many students basically type a word or two into Google search or digital libraries, often resulting in way too large a result of set data. It can result in irrelevant data being found which is frustrating if students’ sources do not match what they are looking for with all the information found. This problem is one of students not sure of what keywords to actually use so that finding a particular resource often involves multiple search queries. College students surely do not want to make the error of collecting incorrect or incomplete data during their research.
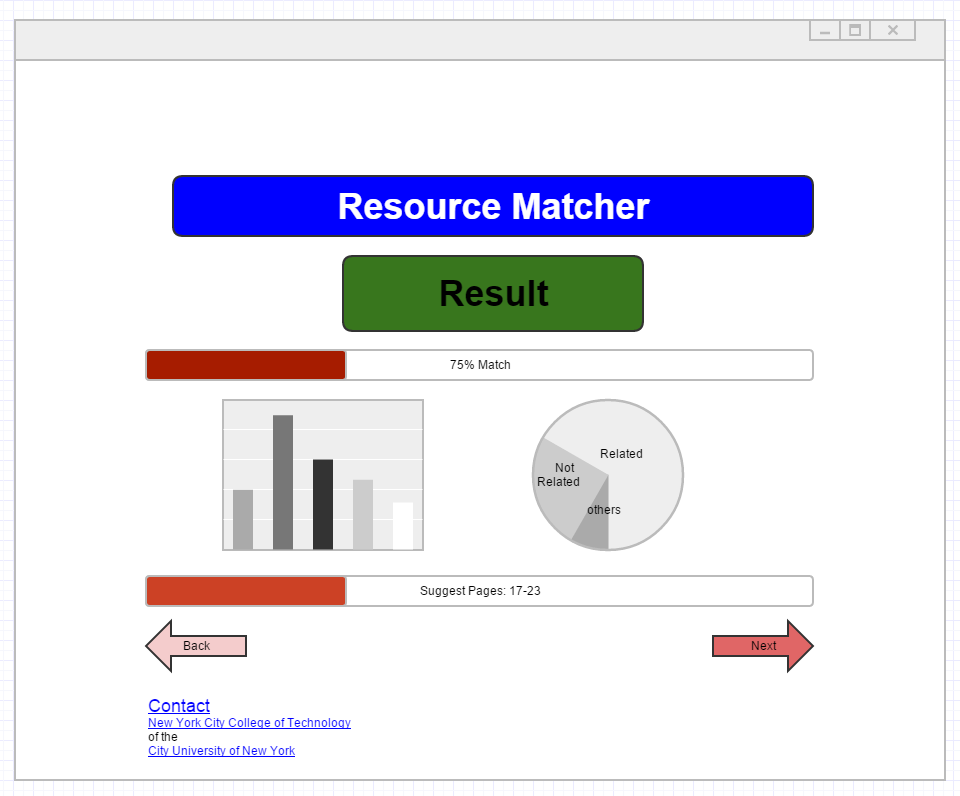
In a Pew survey, a majority of teachers said that their students lacked patience and determination when doing difficult research (Sarah, 2015). Well, we’re about to change that. Our research software, “Source Skimmer” that we developed, can efficiently and precisely handle this. It can quickly scan all your sources, then give you the percentage to closely match the research topic with the sources, which shows an overview of the data like an abstract. The app can efficiently save students’ time.
So how does Source Skimmer make searching more efficient? By matching data and searches our matching network system has taken a step forward within technology and dataset which essentially is a collection of data (Shaorong, 2015). Utilizing Query document matching in web searching allows students to pose one time queries where they will receive relevant resources that match their research assignments (Li & Xu 2012). The software is designed to select the best information sources when performing a search. Source Skimmer has been developed to tackle one of the biggest challenges when searching for data is abroad mismatch. For instance, when performing an online search keywords such as “YouTube”, with variations such as you tub, u tube, yu tube. These are examples of different representations of the same search intent. Our software will show the information from the keywords by matching the resources and suggested pages. It will employ the use of match level settings ranging from specific, specific or generic and specific, generic with text description. What this demonstrates is how using our program can retrieve the data to the most specific or more broadly in terms of data retrieval the student needs. This is similar to ACM DIGITAL LIBRARY which cites search relevance as the most important factor in web searching. As stated in an article from their website, “It has been observed that many hard cases in search relevance are due to a term mismatch between query and document (e.g., query ‘NY Times’ does not match well with document only containing ‘new York times’), and thus it is not exaggerated to say that dealing with the mismatch between query and document is one of the most critical research problems in web search (Li, Xu 2012). Also, as students rely on Wikipedia for quick searches, as it is not always a reliable or accurate source for information was taken into account during the development phase. Source skimmer will not only combine the search for strings for specific objects like persons, locations and definitions, but also to search for categories. In this way, the software will understand text in an efficient and not in an obscure manner when tasked with searching and analyzing search content. This took a similar approach to the one used by a company called AISA Software. One of their principle scientists explained that by, “With our new technique we can not only build better search engines, but also make computers understand texts almost as a human does, in an efficient way”. “In this way, the search for “Angela Merkel + phone call + Ukrainian politicians” results in texts dealing with the German Chancellor within the context of Ukrainian politicians like “Yulia Tymoshenko” and the string “phone call” (Staff, 2014).
As demonstrated, Source Skimmer is designed to take the guess work out of web searches and give the student a near perfect match in the data they seek. It will be available for use as an app on your smartphone or can be downloaded for use on a computer. It will be licensed through the CUNY system for all undergraduates to use and the cost to use will be part of their Technology Fee.
References
Li, H., & Xu, J. (2012). Machine learning for query-document matching in search. Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, 767-768. doi:10.1145/2124295.2124393
Sarah, M. (2015, September 30). Helping Students Become Better Online Researchers. Retrieved from http://www.edudemic.com/students-better-online-researchers/
Shaorong, Z., & Yu, X. (2015). Research Into Modularized Educational Equilibrium Information System Based on Automatic Network Matching. Canadian Social Science, 11(4), 12-116. doi:10.3968/6801
Staff, N. (2014, February 26). AIDA Software Makes Vague Online Searching More Accurate. SCIENTIFIC BLOGGING. Retrieved from http://www.science20.com/news_articles/aida_software_makes_vague_online_searchingmore_accurate-130516