
I encourage you to read Nate Silver’s book The Signal and the Noise at some point (there is a copy in the CityTech library), since it discusses a number of applications of statistics and probability. Hence, it raises a number of different ideas for projects. Here is an outline of the topics of the book, along with some project ideas:
- Chapter 1 (“A Catastrophic Failure of Prediction”) discusses the financial crisis of 2007. It starts by looking at mortgage-backed securities (MBS) and collateralized debt obligations (CDOs), and how the credit ratings agencies miscalculated the probabilities of default on such securities, and underestimated how such defaults could be correlated. One idea for a project is to go through the simplified CDO example that Silver presents in this chapter, and more generally look at probabilities and risk in such “fixed income” securities (the simplest of which are bonds). A related article to look at for this is a 2009 Wired article titled “Recipe for Disaster: The Formula That Killed Wall Street“.
- Chapter 2 (“Are You Smarter Than a Television Pundit?”) discusses predictions and punditry in politics. It also introduces one of the central themes of the book: “thinking probabilistically.” Though it’s not explicitly discussed in the book, a great idea for a project would be to look at the details of Silver’s 538 election forecasting model. There is a good writeup on the 538 website: “How The FiveThirtyEight Senate Forecast Model Works“.(Before going into the quantitative details, Silver introduces some principles for a good model, the first one of which is: “Principle 1: A good model should be probabilistic, not deterministic.”)
- Chapter 3 (“All I Care About is W’s and L’s”) discusses Silver’s original foray into statistical modeling: baseball. He tells the story of how he developed his model for forecasting baseball player performance and development, PECOTA. Again, it’s not discussed in detail in the book, but if you’re interested in baseball, a project could look at some of the details of PECOTA (here is something Silver wrote about it), and/or some of the “advanced stats” that have been developed for baseball, such as Win Expectancy, Win Probability Added, or Wins Above Replacement. I have a copy of another book titled “Baseball Between the Numbers” which is a collection of articles about the quantitative/statistical approach to baseball.
Such advanced statistical approaches are also being applied to other sports (often under the heading “advanced stats” or “advanced analytics). For example, a great subject for a project would be to look at a still-developing statistic for basketball called “expected value possession” (EVP). Here is the basic idea, taken from a Grantland article titled “Databall” by a one of the people who is working on it:
Every “state” of a basketball possession has a value. This value is based on the probability of a made basket occurring, and is equal to the total number of expected points that will result from that possession. While the average NBA possession is worth close to one point, that exact value of expected points fluctuates moment to moment, and these fluctuations depend on what’s happening on the floor.
See also this Grantland interview with the two Harvard statistics PhD students who developed this idea, and the paper they presented earlier this year at the annual MIT Sloan Sports Analytics Conference. There’s also this link which goes through an example and relates it to baseball’s Run Expectancy and football’s Expected Points Added.
- Chapter 4 discusses advances in weather forecasting, and includes a little bit about the philosophical debate about “determinism vs. probabilism” and “Laplace’s demon“, before discussing some aspects of chaos theory (namely, sensitivity to initial conditions) and why it means weather forecasts are probabilistic. Silver also presents statistics showing that weather forecasting has been getting steadily better over the past few decades.One project idea would be to look at how probability is used in weather forecasting; there is an article by two meteorologists from the National Oceanic & Atmospheric Administration’s National Severe Storms Laboratory on “Probability Forecasting“. You could also look at the technique of “ensemble forecasting,” which is alluded to in Silver’s chapter.
- Chapter 5 (“Desperately Seeking Signal”) describes the difficulty of predicting earthquakes from data. Some concepts discussed here that could lead to projects are the Gutenberg–Richter law, which “posits that there is a simple relationship between the magnitude of an earthquake and how often one occurs.”
This is part of a model used by the United States Geological Survey to calculate the probability of an earthquake occurring at any given location within a given time frame. See the USGS link Earthquake Probability Mapping, which was used to generate this map of earthquake probabilities for our region:
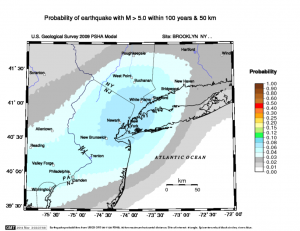
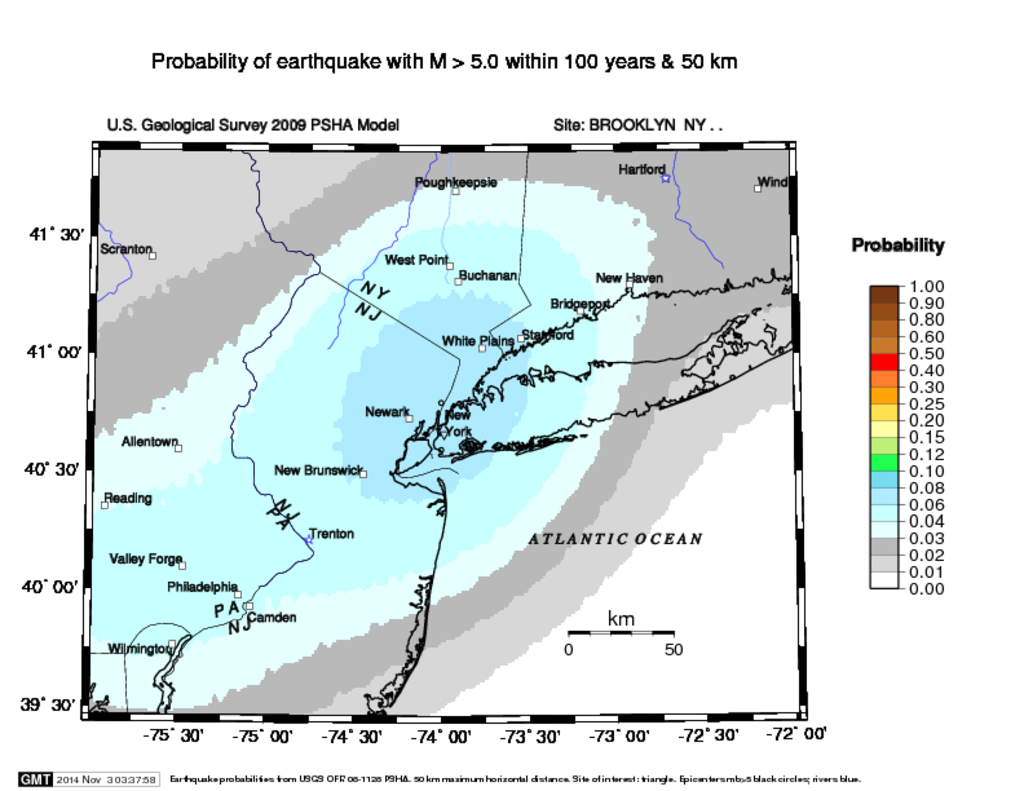
Outline to be completed:
- Chapter 6: economic forecasting
- Chapter 7: infectious diseases
- Chapter 8: gambling on sports (and Bayesian statistics)
- Chapter 9, “Rage Against the Machines”: computer chess (which was also the subject of a short film on FiveThirtyEight’s website: “Exploring The Epic Chess Match Of Our Time“)
- Chapter 10, “The Poker Bubble”: the probabilities (and economics) of poker
- Chapter 11 returns to some topics in finance, with a focus on the efficient-market hypothesis and financial bubbles. There has been a lot of statistical work on testing the efficient market hypothesis, some of which Silver discusses, and which could be a good topic for a project, especially if you’re interested in the stock market.
- Chapter 12, “A Climate of Healthy Skepticism”: climate forecasting and predictions of global warming
- Chapter 13 focuses on terrorism, including statistics of terror attack frequency

