Contents
The Chi-Square Test
The χ2 statistic is used in genetics to illustrate if there are deviations from the expected outcomes of the alleles in a population. The general assumption of any statistical test is that there are no significant deviations between the measured results and the predicted ones. This lack of deviation is called the null hypothesis (H0). χ2 statistic uses a distribution table to compare results against at varying levels of probabilities or critical values. If the χ2 value is greater than the value at a specific probability, then the null hypothesis has been rejected and a significant deviation from predicted values was observed. Using Mendel’s laws, we can count phenotypes after a cross to compare against those predicted by probabilities (or a Punnett Square).
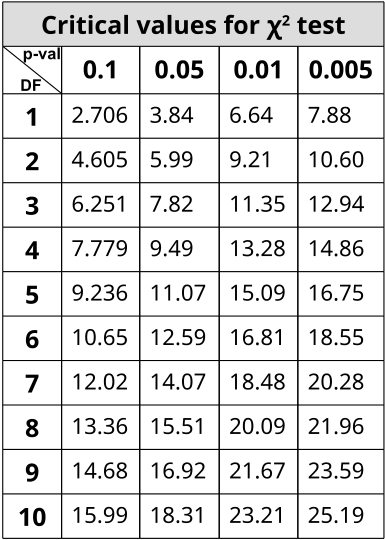 In order to use the table, one must determine the stringency of the test. The lower the p-value, the more stringent the statistics. Degrees of Freedom (DF) are also calculated to determine which value on the table to use. Degrees of Freedom are the number of classes or categories there are in the observations minus 1. DF=n-1
In order to use the table, one must determine the stringency of the test. The lower the p-value, the more stringent the statistics. Degrees of Freedom (DF) are also calculated to determine which value on the table to use. Degrees of Freedom are the number of classes or categories there are in the observations minus 1. DF=n-1
In the example of corn kernel color and texture, there are 4 classes: Purple & Smooth, Purple & Wrinkled, Yellow & Smooth, Yellow & Wrinkled. Therefore, DF = 4 – 1 = 3 and choosing p < 0.05 to be the threshold for significance (rejection of the null hypothesis), the χ2 must be greater than 7.82 in order to be significantly deviating from what is expected. With this dihybrid cross example, we expect a ratio of 9:3:3:1 in phenotypes where 1/16th of the population are recessive for both texture and color while 9/16th of the population display both color and texture as the dominant. 3/16th will be dominant for one phenotype while recessive for the other and the remaining 3/16th will be the opposite combination.
With this in mind, we can predict or have expected outcomes using these ratios. Taking a total count of 200 events in a population, 9/16(200)=112.5 and so forth. Formally, the χ2 value is generated by summing all combinations of:
(observed-expected)2/expected
Chi-Square Test: Is this coin fair or weighted? (activity)
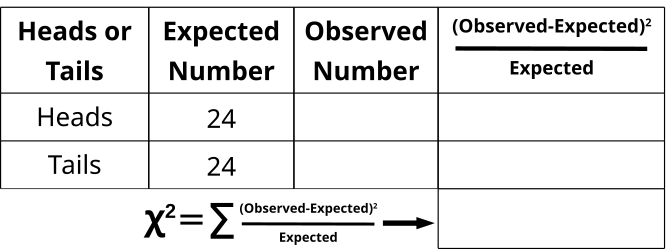
- Everyone in the class should flip a coin 2x and record the result (assumes class is 24)
- Fair coins are expected to land 50% heads and 50% tails
- 50% of 48 results should be 24
- 24 heads and 24 tails is already written in the “Expected” column
- As a class, compile the results in the “Observed” column (total of 48 coin flips)
- In the last column, subtract the expected heads from the observed heads and square it, then divide by the number of expected heads
- In the last column, subtract the expected tails from the observed tails and square it, then divide by the number of expected tails
- Add the values together from the last column to generate the χ2 value
- Compare the value with the value at 0.05 with DF=1
- there are 2 classes or categories (head or tail), so DF = 2 – 1 = 1
- Were the coin flips fair (not significantly deviating from 50:50)?
Let’s say that the coin tosses yielded 26 Heads and 22 Tails. Can we assume that the coin was unfair? If we toss a coin an odd number of times (eg. 51), then we would expect that the results would yield 25.5 (50%) Heads and 25.5 (50%) Tails. But this isn’t a possibility. This is when the χ2 test is important as it delineates whether 26:25 or 30:21 etc. are within the probability for a fair coin.
Chi-Square Test of Kernel Coloration and Texture in an F2 Population (activity)
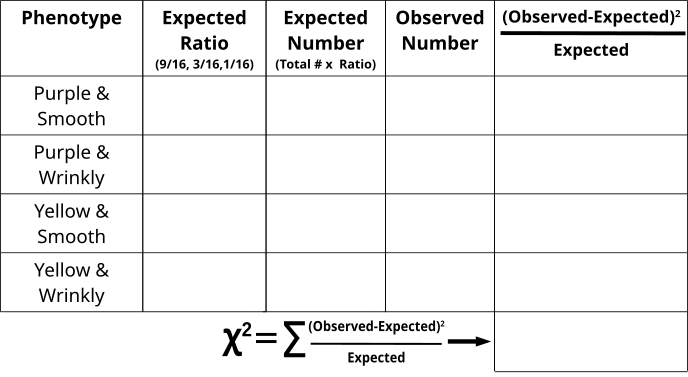
- From the counts, one can assume which phenotypes are dominant and recessive
- Fill in the “Observed” category with the appropriate counts
- Fill in the “Expected Ratio” with either 9/16, 3/16 or 1/16
- The total number of counted event was 200, so multiply the “Expected Ratio” x 200 to generate the “Expected Number” fields
- Calculate the (Observed-Expected)2/Expected for each phenotype combination
- Add all (Observed-Expected)2/Expected values together to generate the χ2 value and compare with the value on the table where DF=3
- Do we reject the Null Hypothesis or were the observed numbers as we expected as roughly 9:3:3:1?
- What would it mean if the Null Hypothesis was rejected? Can you explain a case in which we have observed values that are significantly altered from what is expected?
Tags: quantitative reasoning, integration of knowledge, guided inquiry

